UBICOMP / ISWC 2020
DETAILED PROGRAM AND VIDEOS
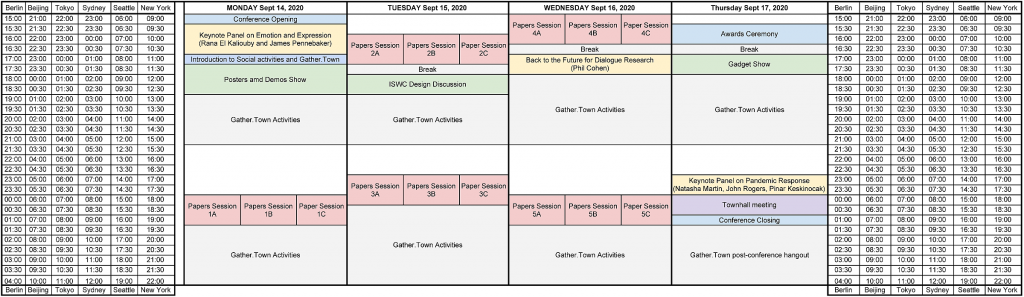
Keynotes
Keynotes on Emotion and Expression
Keynote on Conversational Systems
Keynote on Pandemics
Plenaries
Conference Opening
Awards, Gadget Show, Town Hall
Gather Town
Sessions
Monday, September 14, 2020 18:00-19:30 EDT
Session 1A: ‘Security, Privacy, and Acceptance’ [view papers here]
Session 1B: ‘Displays, Tactile, and New Interaction’ [view papers here]
Session 1C: ‘Sensing I (Behaviour and Emotions)’ [view papers here]
Tuesday, September 15, 2020 10:00-11:30 EDT
Session 2A: ‘Low-Power and Energy Harvesting’ [view papers here]
Session 2B: ‘Health and Wellbeing I’ [view papers here]
Session 2C: ‘Sensing II (Context and Environment)’ [view papers here]
Tuesday, September 15, 2020 17:00-18:30 EDT
Session 3A: ‘Location and Human Mobility’ [view papers here]
Session 3B: ‘Touch, Gestures, and Posture’ [view papers here]
Session 3C: ‘Sensing III (RF and other sensing modes)’ [view papers here]
Wednesday, September 16, 2020 09:00-10:30 EDT
Session 4A: ‘IoT and Software Tools’ [view papers here]
Session 4B: ‘Health and Wellbeing II’ [view papers here]
Session 4C: ‘Human Activity Recognition I’ [view papers here]
Wednesday, September 16, 2020 18:00-19:30 EDT
Session 5A: ‘Driving and Transportation’ [view papers here]
Session 5B: ‘Speech interaction + Fabrication’ [view papers here]
- Session 5C: ‘Human Activity Recognition II’ [view papers here]
Papers by Session
Session 1A: ‘Security, Privacy, and Acceptance’
Monday, September 14, 2020 18:00-19:30 EDT
As a part of this trend, modern transportation systems are equipped with public WiFi devices to provide Internet access for passengers as people spend a large amount of time on public transportation in their daily life.
However, one of the key issues in public WiFi spots is the privacy concern due to its open access nature.
Existing works either studied location privacy risk in human traces or privacy leakage in private networks such as cellular networks based on the data from cellular carriers.
To the best of our knowledge, none of these work has been focused on bus WiFi privacy based on large-scale real-world data.
In this paper, to explore the privacy risk in bus WiFi systems, we focus on two key questions how likely bus WiFi users can be uniquely re-identified if partial usage information is leaked and how we can protect users from the leaked information.
To understand the above questions, we conduct a case study in a large-scale bus WiFi system, which contains 20 million connection records and 78 million location records from 770 thousand bus WiFi users during a two-month period.
Technically, we design two models for our uniqueness analyses and protection, i.e., a PB-FIND model to identify the probability a user can be uniquely re-identified from leaked information;
a PB-HIDE model to protect users from potentially leaked information.
Specifically, we systematically measure the user uniqueness on users’ finger traces (i.e., connection URL and domain), foot traces (i.e., locations), and hybrid traces (i.e., both finger and foot traces).
Our measurement results reveal
(i) 97.8% users can be uniquely re-identified by 4 random domain records of their finger traces and 96.2% users can be uniquely re-identified by 5 random locations on buses;
(ii) 98.1% users can be uniquely re-identified by only 2 random records if both their connection records and locations are leaked to attackers.
Moreover, the evaluation results show
our PB-HIDE algorithm protects more than 95% users from the potentially leaked information by inserting only 1.5% synthetic records in the original dataset to preserve their data utility.
This work departs from prior works in methodology: we leverage adversarial learning to a better balance between privacy and utility. We design a representation encoder that generates the feature representations to optimize against the privacy disclosure risk of sensitive information (a measure of privacy) by the privacy adversaries and concurrently optimize with the task inference accuracy (a measure of utility) by the utility discriminator. The result is the privacy adversarial network (PAN), a novel deep model with the new training algorithm, that can automatically learn representations from the raw data. And the trained encoder can be deployed on the user side to generate representations that satisfy the task-defined utility requirements and the user-specified/agnostic privacy budgets.
Intuitively, PAN adversarially forces the extracted representations to only convey the information required by the target task. Surprisingly, this constitutes an implicit regularization that actually improves task accuracy. As a result, PAN achieves better utility and better privacy at the same time! We report extensive experiments on six popular datasets and demonstrate the superiority of PAN compared with alternative methods reported in prior work.
Session 1B: ‘Displays, Tactile, and New Interaction’
Monday, September 14, 2020 18:00-19:30 EDT
The detection of disturbances of such an experience that occur over time, namely breaks in presence (BIP), enables the evaluation and improvement of these.
Existing methods do not detect BIPs, e.g., questionnaires, or are complex in their application and evaluation, e.g., physiological and behavioral measures.
We propose a handy post-experience method in which users reflect on their experienced state of presence by drawing a line in a paper-based drawing template.
The amplitude of the drawn line represents the state of presence of the temporal progress of the experience.
We propose a descriptive model that describes temporal variations in the drawings by the definition of relevant points over time, e.g., putting on the HMD, phases of the experience, transition into VR, and parameters, e.g., the transition time.
The descriptive model enables us to objectively evaluate user drawings and represent the course of the drawings by a defined set of parameters.
Our exploratory user study (N=30) showed that the drawings are very consistent between participants and the method is able to securely detect a variety of BIPs.
Moreover, the results indicate that the method might be used in the future to evaluate the strength of BIPs and to reflect the temporal course of a presence experience in detail.
Additional application examples and a detailed discussion pave the way for others to use our method.
Further, they serve as a motivation to continue working on the method and the general understanding of temporal fluctuations of the presence experience.
Session 1C: ‘Sensing I (Behaviour and Emotions)’
Monday, September 14, 2020 18:00-19:30 EDT
We developed MyMood, a smartphone application that allows users to periodically log their emotional state together with pictures from their everyday lives, while passively gathering sensor measurements. We conducted an in-the-wild study with 22 participants and collected 3,305 mood reports with photos. Our findings show context-dependent associations between objects surrounding individuals and self-reported emotional state intensities. The applications of this work are potentially many, from the design of interior and outdoor spaces to the development of intelligent applications for positive behavioral intervention, and more generally for supporting computational psychology studies.
Session 2A: ‘Low-Power and Energy Harvesting’
Tuesday, September 15, 2020 10:00-11:30 EDT
To overcome this challenge, we propose a new design to embed inductively coupled coil pairs adjacent to glasses hinges to deliver power and data wirelessly to the frames.
Positioning the coils next to the hinges creates sufficient area for a large transmission and reception coil while maintaining the utility of the glasses.
Consequently, we were able to achieve over 85% power efficiency and a communication rate of 50~Mbps between coils that are small enough to be embedded inside the frame of conventional glasses, available on the market.
Session 2B: ‘Health and Wellbeing I’
Tuesday, September 15, 2020 10:00-11:30 EDT
collect a data set of of continuous streams of sensor data captured from personal devices along with labels indicating whether a user is working or taking a break. We use multiple instruments to facilitate the collection of users’ self-reported labels and discuss our experience with this approach. We analyse the available data – 449 labelled activities of nine knowledge workers collected during a typical work week – using machine learning techniques and show that user-independent models can achieve a (F1 score) of 94% for the identification of work activities and of 69% for breaks, outperforming baseline methods by 5-10 and 12-54 percentage points, respectively.
In this paper, we define the general concept of ‘opportunity’ contexts and apply it to the case of smoking cessation. We operationalize the smoking ‘opportunity’ context, using self-reported smoking allowance and cigarette availability. We show its clinical utility by establishing its association with smoking occurrences using Granger causality. Next, we mine several informative features from GPS traces, including the novel location context of smoking spots, to develop the SmokingOpp model for automatically detecting the smoking ‘opportunity’ context. Finally, we train and evaluate the SmokingOpp model using 15 million GPS points and 3,432 self-reports from 90 newly abstinent smokers in a smoking cessation study.
In this paper, we introduce BodyCompass, the first RF-based system that provides accurate sleep posture monitoring overnight in the user’s own home. BodyCompass works by studying the RF reflections in the environment. It disentangles RF signals that bounced off the subject’s body from other multipath signals. It then analyzes those signals via a custom machine learning algorithm to infer the subject’s sleep posture. BodyCompass is easily transferable and can apply to new homes and users with minimal effort. We empirically evaluate BodyCompass using over 200 nights of sleep data from 26 subjects in their own homes. Our results show that, given one week, one night, or 16 minutes of labeled data from the subject, BodyCompass’s corresponding accuracy is 94%, 87%, and 84%, respectively.
Session 2C: ‘Sensing II (Context and Environment)’
Tuesday, September 15, 2020 10:00-11:30 EDT
To address these challenges, we propose a machine learning approach to forecast the fire risk, entitled NeuroFire. NeuroFire can represent internal and external temporal effect then combine the temporal representation and spatial dependencies by a spatial-temporal loss function.
Experimental evaluations on real-world datasets show that our NeuroFire outperforms 9 baselines, demonstrating the performance of our approach by several visualizations. Moreover, we implement a citywide fire forecasting system named CityGuard to display the analysis and forecasting results, which can assist the fire rescue department in deploying fire prevention.
To evaluate our algorithm, a half-year data collection was deployed with a real-world system on a coastal area including the Sino-Singapore Tianjin Eco-city in north China. With the resolution of 500m×500m×1h, our offline method is proved to have high robustness against low sampling coverage and accidental sensor errors, obtaining 14.9% performance improvement over existing methods. Our quasi real-time model better captures the spatiotemporal dependencies in the pollution map with unevenly distributed samples than other real-time approaches, obtaining 4.2% error reduction.
Session 3A: ‘Location and Human Mobility’
Tuesday, September 15, 2020 17:00-18:30 EDT
To our knowledge, this is the first work studying cellular data usage prediction from an individual user behavior-aware perspective based on large-scale cellular signaling and behavior tags from the subscription data. The results show that our method improves the data usage prediction accuracy compared to the state-of-the-art methods; we also comprehensively demonstrate the impact of contextual factors on CellPred performance.
Our work can shed light on broad cellular networks researches related to human mobility and data usage. Finally, we discuss issues such as limitations, applications of our approach, and insights from our work.
In this paper, we propose StoryTeller, a deep learning-based technique for floor prediction in multi-story buildings. StoryTeller leverages the ubiquitous WiFi signals to generate images that are input to a Convolutional Neural Network (CNN) which is trained to predict floors based on detected patterns in visible WiFi scans. Input images are created such that they capture the current WiFi-scan in an AP-independent manner. In addition, a novel virtual building concept is used to normalize the information in order to make them building-independent. This allows StoryTeller to reuse a trained network for a completely new building, significantly reducing the deployment overhead.
We have implemented and evaluated StoryTeller using three different buildings with a side-by-side comparison with the state-of-the-art floor estimation techniques. The results show that StoryTeller can estimate the user’s floor at least 98.3% within one floor of the actual ground truth floor. This accuracy is consistent across the different testbeds and for scenarios where the models used were trained in a completely different building than the tested building. This highlights StoryTeller’s ability to generalize to new buildings and its promise as a scalable, low-overhead, high-accuracy floor localization system.
To this end, we provide the first attempt to design an effective and efficient scheduling algorithm for the dynamic public resource allocation. We formulate the problem as a novel multi-agent long-term maximal coverage scheduling (MALMCS) problem, which considers the crowd coverage and the energy limitation during a whole day. Two main components are employed in the system: 1) multi-step crowd flow prediction, which makes multi-step crowd flow prediction given the current crowd flows and external factors; and 2) energy adaptive scheduling, which employs a two-step heuristic algorithm, i.e., energy adaptive scheduling (EADS), to generate a scheduling plan that maximizes the crowd coverage within the service time for agents. Extensive experiments based on real crowd flow data in Happy Valley (a popular theme park in Beijing) demonstrate the effectiveness and efficiency of our approach.
Session 3B: ‘Touch, Gestures, and Posture’
Tuesday, September 15, 2020 17:00-18:30 EDT
when the user inputs PIN or pattern. It is robust against the behavioral variability of inputting a passcode and places no restrictions on input manner (e.g., number of the finger touching the screen, moving speed, or pressure). To capture the spatial characteristic of the user’s hand posture shape when input the PIN or pattern, TouchPrint performs active acoustic sensing to scan the user’s hand posture when his/her finger remains static at some reference positions on the screen (e.g., turning points for the pattern and the number buttons for the PIN code), and extracts the multipath effect feature from the echo signals reflected by the hand. Then, TouchPrint fuses with the spatial multipath feature-based identification results generated from the multiple reference positions to facilitate a reliable and secure MFA system. We build a prototype on smartphone and then evaluate the performance of TouchPrint comprehensively in a variety of scenarios. The experiment results demonstrate that TouchPrint can effectively defend against the replay attacks and imitate attacks. Moreover, TouchPrint can achieve an authentication accuracy of about 92% with only ten training samples.
Session 3C: ‘Sensing III (RF and other sensing modes)’
Tuesday, September 15, 2020 17:00-18:30 EDT
To overcome these limitations, we propose MultiSense, the first WiFi-based system that can robustly and continuously sense the detailed respiration patterns of multiple persons even they have very similar respiration rates and are physically closely located. The key insight of our solution is that the commodity WiFi hardware nowadays is usually equipped with multiple antennas. Thus, each individual antenna can receive a different mix copy of signals reflected from multiple persons. We successfully prove that the reflected signals are linearly mixed at each antenna and propose to model the multi-person respiration sensing as a blind source separation (BSS) problem. Then, we solve it using independent component analysis (ICA) to separate the mixed signal and obtain the reparation information of each person. Extensive experiments show that with only one pair of transceivers, each equipped with three antennas, MultiSense is able to accurately monitor respiration even in the presence of four persons, with the mean absolute respiration rate error of 0.73 bpm (breaths per minute).
We present RFTattoo, which to our knowledge is the first wireless speech recognition system for voice impairments using batteryless and flexible RFID tattoos. We design specialized wafer-thin tattoos attached around the user’s face and easily hidden by makeup. We build models that process signal variations from these tattoos to a portable RFID reader to recognize various facial gestures corresponding to distinct classes of sounds. We then develop natural language processing models that infer meaningful words and sentences based on the observed series of gestures. A detailed user study with 10 users reveals 86% accuracy in reconstructing the top-100 words in the English language, even without the users making any sounds.
Prior solutions typically require user to hold a wireless transmitter, or need proprietary wireless hardware. They can only recognize a small set of pre-defined hand gestures. This paper introduces FingerDraw, the first sub-wavelength level finger motion tracking system using commodity WiFi devices, without attaching any sensor to finger.
FingerDraw can reconstruct finger drawing trajectory such as digits, alphabets, and symbols with the setting of one WiFi transmitter and two WiFi receivers. It uses a two-antenna receiver to sense the sub-wavelength scale displacement of finger motion in each direction. The theoretical underpinning of FingerDraw is our proposed CSI-quotient model, which uses the channel quotient between two antennas of the receiver to cancel out the noise in CSI amplitude and the random offsets in CSI phase, and quantifies the correlation between CSI value dynamics and object displacement. This channel quotient is sensitive to and enables us to detect small changes in In-phase and Quadrature parts of channel state information due to finger movement.
Our experimental results show that the overall median tracking accuracy is 1.27 cm, and the recognition of drawing ten digits in the air achieves an average accuracy of over 93.0%.
Session 4A: ‘IoT and Software Tools’
Wednesday, September 16, 2020 09:00-10:30 EDT
EUD activities are applicable to the work practices of psychology researchers and clinicians, who increasingly rely on software for assessment of participants and patients, but must also depend on developers to realise their requirements.
In practice, however, the adoption of EUD technology by these two end-user groups is contingent on various contextual factors that are not well understood.
In this paper, we therefore establish recommendations for the design of EUD tools allowing non-programmers to develop apps to collect data from participants in their everyday lives, known as “experience sampling” apps.
We first present interviews conducted with psychology researchers and practising clinicians on their current working practices and motivation to adopt EUD tools. We then describe our observation of a chronic disease management clinic. Finally, we describe three case studies of psychology researchers using our EUD tool Jeeves to undertake experience sampling studies, and synthesise recommendations and requirements for tools allowing the EUD of experience sampling apps.
Session 4B: ‘Health and Wellbeing II’
Wednesday, September 16, 2020 09:00-10:30 EDT
We define several metrics to gauge receptivity towards the interventions, and found that (1) several participant-specific characteristics (age, personality, and device type) show significant associations with the overall participant receptivity over the course of the study, and that (2) several contextual factors (day/time, phone battery, phone interaction, physical activity, and location), show significant associations with the participant receptivity, in-the-moment. Further, we explore the relationship between the effectiveness of the intervention and receptivity towards those interventions; based on our analyses, we speculate that being receptive to interventions helped participants achieve physical activity goals, which in turn motivated participants to be more receptive to future interventions. Finally, we build machine-learning models to detect receptivity, with up to a 77% increase in F1 score over a biased random classifier.
searching a large food database on a small mobile screen. We describe the design of the EaT (Eat and Track) app with its
Search-Accelerator to support searches on >6,000 foods. We designed a study to harness data from a large nutrition study to provide insights about the use and user experience of EaT. We report the results of our evaluation: a 12-participant lab study and a public health research field study where 1,027-participants entered their nutrition intake for 3 days, logging 30,715 food items. We also analysed 1,163 user-created food entries from 670 participants to gain insights about the causes of failures in the food search. Our core contributions are: 1) the design and evaluation of EaT’s support for accurate and detailed food logging; 2) our study design that harnesses a nutrition research study to provide insights about timeliness of logging and the strengths and weaknesses of the search; 3) new performance benchmarks for mobile food logging.
More than one million people in the US suffer from hemianopia, which blinds the vision in one half of the peripheral vision in both eyes. Hemianopic patients are often not aware of what they cannot see and frequently bump into walls, trip over objects, or walk into people on the side where the peripheral vision is diminished. We present an augmented reality based assistive technology that expands the peripheral vision of hemianopic patients at all distances. In a pilot trial, we evaluate the utility of this assistive technology for ten hemianopic patients. We measure and compare outcomes related to target identification and visual search in the participants. Improvements in target identification are noted in all participants ranging from 18% to 72%. Similarly, all the participants benefit from the assistive technology in performing a visual search task with an average increase of 24% in the number of successful searches compared to unaided trials. The proposed technology is the first instance of an electronic vision enhancement tool for hemianopic patients and is expected to maximize the residual vision and quality of life in this growing, yet largely overlooked population.
Session 4C: ‘Human Activity Recognition I’
Wednesday, September 16, 2020 09:00-10:30 EDT
Session 5A: ‘Driving and Transportation’
Wednesday, September 16, 2020 18:00-19:30 EDT
We implement RISC on a Chinese city Shenzhen with one-month real-world data from (i) a taxi fleet with 14 thousand vehicles; (ii) a bus fleet with 13 thousand vehicles; (iii) a truck fleet with 4 thousand vehicles. Further, we design an application, i.e., track suspect vehicles (e.g., hit-and-run vehicles), to evaluate the performance of RISC on the urban sensing aspect based on the data from a regular vehicle (i.e., personal car) fleet with 11 thousand vehicles. The evaluation results show that compared to the state-of-the-art solutions, we improved sensing coverage (i.e., the number of road segments covered by sensing vehicles) by 10% on average.
In this paper, we present two novel and practical approaches for continuous driver monitoring in low-light conditions: (i) Image synthesis: enabling monitoring in low-light conditions using just the smartphone RGB camera by synthesizing a thermal image from RGB with a Generative Adversarial Network, and (ii) Near-IR LED: using a low-cost near-IR (NIR) LED attachment to the smartphone, where the NIR LED acts as a light source to illuminate the driver’s face, which is not visible to the human eyes, but can be captured by standard smartphone cameras without any specialized hardware. We show that the proposed techniques can capture the driver’s face accurately in low-lighting conditions to monitor driver’s state. Further, since NIR and thermal imagery is significantly different than RGB images, we present a systematic approach to generate labelled data, which is used to train existing computer vision models. We present an extensive evaluation of both the approaches with data collected from 15 drivers in controlled basement area and on real roads in low-light conditions. The proposed NIR LED setup has an accuracy (F1-score) of 85% and 93.8% in detecting driver fatigue and distraction, respectively in low-light.
In this paper, we propose CARIN, CSI-based driver Activity Recognition under the INterference of passengers. CARIN features a combination-based solution that profiles all the possible activity combinations of driver and (one or more) passengers in offline training and then performs recognition online. To attack possible combination explosion, we first leverage in-car pressure sensors to significantly reduce combinations, because there are only limited seating options in a passenger vehicle. We then formulate a distance minimization problem for fast runtime recognition. In addition, a period analysis methodology is designed based on the kNN classifier to recognize activities that have a sequence of body movements, like continuous head nodding due to driver fatigue. Our results in a real car with 3,000 real-world traces show that CARIN can achieve an overall F1 score of 90.9%, and outperform the three state-of-the-art solutions by 32.2%.
More importantly, we simulate and evaluate FairCharge with real-world streaming data from the Chinese city Shenzhen, including GPS data and transaction data from more than 16,400 electric taxis, coupled with the data of 117 charging stations, which constitute, to our knowledge, the largest electric taxi network in the world.
The extensive experimental results show that our fairness-aware FairCharge effectively reduces queuing time and idle time of the Shenzhen electric taxi fleet by 80.2% and 67.7%, simultaneously.
Session 5B: ‘Speech interaction + Fabrication’
Wednesday, September 16, 2020 18:00-19:30 EDT
Through our novel set of sensing and fabrication techniques, we enable human activity recognition at room-scale and across a variety of materials. Our techniques create objects that appear the same as typical passive objects, but contain internal fiber optics for both input sensing and simple displays. We use a new fabrication device to inject optical fibers into CNC milled molds. Fiber Bragg Grating optical sensors configured as very sensitive vibration sensors are embedded in these objects. These require no internal power, can be placed at multiple locations along with a single fiber, and can be interrogated from the end of the fiber. We evaluate the performance of our system by creating two full-scale application prototypes: an interactive wall, and an interactive table. With these prototypes, we demonstrate the ability of our system to sense a variety of human activities across eight different users. Our tests show that with suitable materials these sensors can detect and classify both direct interactions (such as tapping) and more subtle vibrations caused by activities such as walking across the floor nearby.
This paper also introduces the design parameters required for well-functioning actuators and studies the properties of such actuators. The crucial element of actuator is a helical planer coil manufactured from “capillary” silver TPU (Thermoplastic polyurethane), an ultra-stretchable conductor. This paper leverages the novel material to manufacture soft vibration actuators in fewer and simpler steps than previous approaches. Best practice and procedure for building a wearable actuator are reported. We show that dimension of actuators are easily configurable and can be printed in batch-size-one using 3D printing. Actuators can be attached directly to the skin as all the components of FLECTILE are made from biocompatible polymers. Tests on the driving properties have confirmed that the actuator could reach a broad scope of frequency up to 200 Hz with a small voltage (5 V) required. A user study showed that vibrations of the actuator are well perceivable by six study participants under an observing, hovering, and resting condition.
Session 5C: ‘Human Activity Recognition II’
Wednesday, September 16, 2020 18:00-19:30 EDT
In line-production systems, each factory worker repetitively performs a predefined work process with each process consisting of a sequence of operations.
Because of the difficulty in collecting labeled sensor data from each factory worker, unsupervised factory activity recognition has been attracting attention in the ubicomp community.
However, prior unsupervised factory activity recognition methods can be adversely affected by any outlier activities performed by the workers.
In this study, we propose a robust factory activity recognition method that tracks frequent sensor data motifs, which can correspond to particular actions performed by the workers, that appear in each iteration of the work processes.
Specifically, this study proposes tracking two types of motifs: period motifs and action motifs, during the unsupervised recognition process.
A period motif is a unique data segment that occurs only once in each work period (one iteration of an overall work process).
An action motif is a data segment that occurs several times in each work period, corresponding to an action that is performed several times in each period.
Tracking multiple period motifs enables us to roughly capture the temporal structure and duration of the work period even when outlier activities occur.
Action motifs, which are spread throughout the work period, permit us to precisely detect the start time of each operation.
We evaluated the proposed method using sensor data collected from workers in actual factories and achieved state-of-the-art performance.
In our experiment use weight transfer to transfer models between two datasets, as well as between sensors from the same dataset. As source- and target- datasets PAMAP2 and Skoda Mini Checkpoint are used. The utilized network architecture is based on a DeepConvLSTM.
The result of our investigation shows that transfer learning has to be considered in a very differentiated way, since the desired positive effects by applying the method depend very much on the data and also on the architecture used.
IMPORTANT DATES
Virtual Conference: September 12-17, 2020
Paper Sessions: September 14-17, 2020
CONTACT
Past Conferences
The ACM international joint conference on pervasive and ubiquitous computing (ubicomp) is the result of a merger of the two most renowned conferences in the field: pervasive and ubicomp. while it retains the name of the latter in recognition of the visionary work of mark weiser, its long name reflects the dual history of the new event. a complete list of both ubicomp and pervasive past conferences is provided below.
UbiComp 2019, London, England
UbiComp 2018, Singapore
UbiComp 2017, Maui, USA
UbiComp 2016, Heidelberg, Germany
UbiComp 2015, Osaka, Japan
UbiComp 2014, Seattle, USA
UbiComp 2013, Zurich, Switzerland
UbiComp 2012, Pittsburgh (PA), USA
Pervasive 2012, Newcastle, England
UbiComp 2011, Beijing, China